“I am working on a simulation study that requires me to generate data for individuals within clusters, but each individual will have repeated measures (say baseline and two follow-ups). I’m new to simstudy and have been going through the examples in R this afternoon, but I wondered if this was possible in the package, and if so whether you could offer any tips to get me started with how I would do this?”
[Read More]Simulating an open cohort stepped-wedge trial
In a current multi-site study, we are using a stepped-wedge design to evaluate whether improved training and protocols can reduce prescriptions of anti-psychotic medication for home hospice care patients with advanced dementia. The study is officially called the Hospice Advanced Dementia Symptom Management and Quality of Life (HAS-QOL) Stepped Wedge Trial. Unlike my previous work with stepped-wedge designs, where individuals were measured once in the course of the study, this study will collect patient outcomes from the home hospice care EHRs over time. This means that for some patients, the data collection period straddles the transition from control to intervention.
[Read More]Analyzing a binary outcome arising out of within-cluster, pair-matched randomization
A key motivating factor for the simstudy package and much of this blog is that simulation can be super helpful in understanding how best to approach an unusual, or least unfamiliar, analytic problem. About six months ago, I described the DREAM Initiative (Diabetes Research, Education, and Action for Minorities), a study that used a slightly innovative randomization scheme to ensure that two comparison groups were evenly balanced across important covariates. At the time, we hadn’t finalized the analytic plan. But, now that we have started actually randomizing and recruiting (yes, in that order, oddly enough), it is important that we do that, with the help of a little simulation.
simstudy updated to version 0.1.14: implementing Markov chains
I’m developing study simulations that require me to generate a sequence of health status for a collection of individuals. In these simulations, individuals gradually grow sicker over time, though sometimes they recover slightly. To facilitate this, I am using a stochastic Markov process, where the probability of a health status at a particular time depends only on the previous health status (in the immediate past). While there are packages to do this sort of thing (see for example the markovchain package), I hadn’t yet stumbled upon them while I was tackling my problem. So, I wrote my own functions, which I’ve now incorporated into the latest version of simstudy that is now available on CRAN. As a way of announcing the new release, here is a brief overview of Markov chains and the new functions. (See here for a more complete list of changes.)
Bayes models for estimation in stepped-wedge trials with non-trivial ICC patterns
Continuing a series of posts discussing the structure of intra-cluster correlations (ICC’s) in the context of a stepped-wedge trial, this latest edition is primarily interested in fitting Bayesian hierarchical models for more complex cases (though I do talk a bit more about the linear mixed effects models). The first two posts in the series focused on generating data to simulate various scenarios; the third post considered linear mixed effects and Bayesian hierarchical models to estimate ICC’s under the simplest scenario of constant between-period ICC’s. Throughout this post, I use code drawn from the previous one; I am not repeating much of it here for brevity’s sake. So, if this is all new, it is probably worth glancing at before continuing on.
[Read More]Estimating treatment effects (and ICCs) for stepped-wedge designs
In the last two posts, I introduced the notion of time-varying intra-cluster correlations in the context of stepped-wedge study designs. (See here and here). Though I generated lots of data for those posts, I didn’t fit any models to see if I could recover the estimates and any underlying assumptions. That’s what I am doing now.
My focus here is on the simplest case, where the ICC’s are constant over time and between time. Typically, I would just use a mixed-effects model to estimate the treatment effect and account for variability across clusters, which is easily done in R using the lme4 package; if the outcome is continuous the function lmer is appropriate. I thought, however, it would also be interesting to use the rstan package to fit a Bayesian hierarchical model.
More on those stepped-wedge design assumptions: varying intra-cluster correlations over time
In my last post, I wrote about within- and between-period intra-cluster correlations in the context of stepped-wedge cluster randomized study designs. These are quite important to understand when figuring out sample size requirements (and models for analysis, which I’ll be writing about soon.) Here, I’m extending the constant ICC assumption I presented last time around by introducing some complexity into the correlation structure. Much of the code I am using can be found in last week’s post, so if anything seems a little unclear, hop over here.
[Read More]Planning a stepped-wedge trial? Make sure you know what you're assuming about intra-cluster correlations ...
A few weeks ago, I was at the annual meeting of the NIH Collaboratory, which is an innovative collection of collaboratory cores, demonstration projects, and NIH Institutes and Centers that is developing new models for implementing and supporting large-scale health services research. A study I am involved with - Primary Palliative Care for Emergency Medicine - is one of the demonstration projects in this collaboratory.
The second day of this meeting included four panels devoted to the design and analysis of embedded pragmatic clinical trials, and focused on the challenges of conducting rigorous research in the real-world context of a health delivery system. The keynote address that started off the day was presented by David Murray of NIH, who talked about the challenges and limitations of cluster randomized trials. (I’ve written before on issues related to clustered randomized trials, including here.)
[Read More]Don't get too excited - it might just be regression to the mean
It is always exciting to find an interesting pattern in the data that seems to point to some important difference or relationship. A while ago, one of my colleagues shared a figure with me that looked something like this:
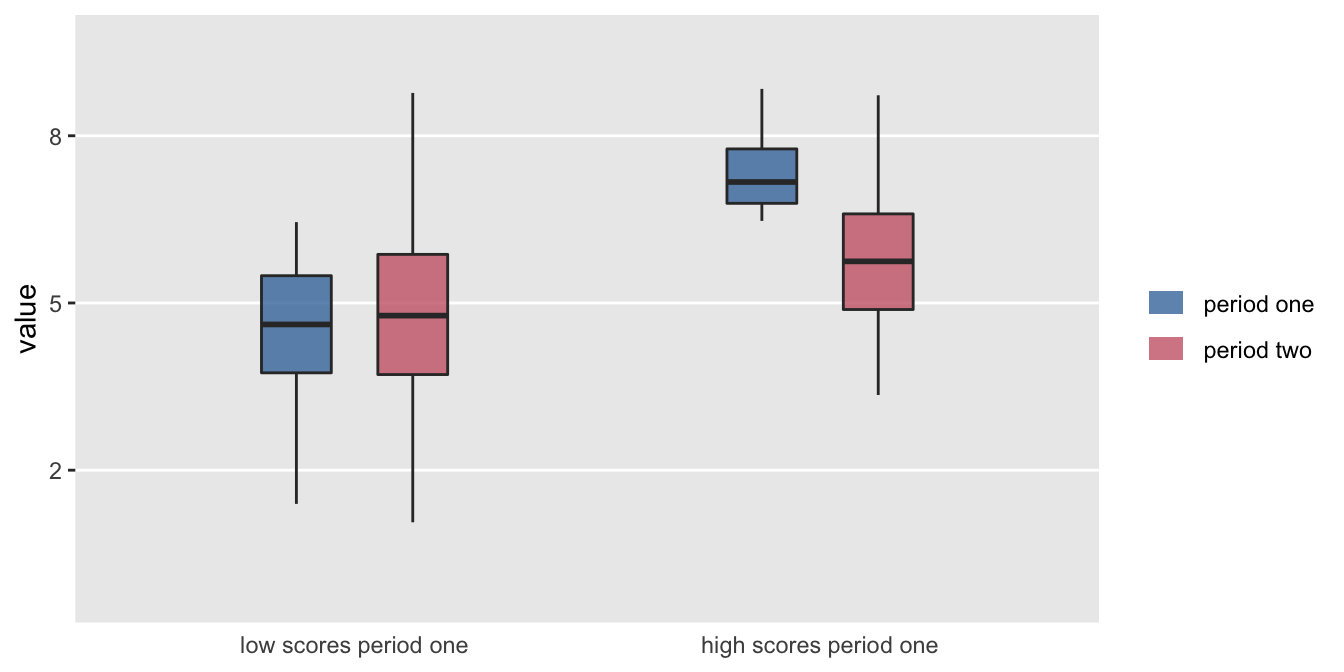
It looks like something is going on. On average low scorers in the first period increased a bit in the second period, and high scorers decreased a bit. Something is going on, but nothing specific to the data in question; it is just probability working its magic.
[Read More]simstudy update - stepped-wedge design treatment assignment
simstudy has just been updated (version 0.1.13 on CRAN), and includes one interesting addition (and a couple of bug fixes). I am working on a post (or two) about intra-cluster correlations (ICCs) and stepped-wedge study designs (which I’ve written about before), and I was getting tired of going through the convoluted process of generating data from a time-dependent treatment assignment process. So, I wrote a new function, trtStepWedge, that should simplify things.