About two years ago, someone inquired whether simstudy had the functionality to generate data from a logistic model with a specific AUC. It did not, but now it does, thanks to a paper by Peter Austin that describes a nice algorithm to accomplish this. The paper actually describes a series of related algorithms for generating coefficients that target specific prevalence rates, risk ratios, and risk differences, in addition to the AUC. simstudy has a new function logisticCoefs that implements all of these. (The Austin paper also describes an additional algorithm focused on survival outcome data and hazard ratios, but that has not been implemented in simstudy). This post describes the the new function and provides some simple examples.
A little background …
In simstudy, there are at least two ways to define a binary data generating process. The first is to operate on the scale of the proportion or probability using the identity link. This allows users to define a data generating process that reflects assumptions about risk ratios and risk differences when comparing two groups defined by an exposure or treatment. However, this process can become challenging when introducing other covariates, because it can be difficult to constrain the probabilities so that they fall between 0 and 1.
The second approach works on the log-odds scale using a logit link, and is much more amenable to accommodating covariates. Unfortunately, this comes at the price of being able to easily generate specific risk ratios and risk differences, because all parameters are log-odds ratios. The overall (marginal) prevalence of an outcome in a population will vary depending on the distribution of covariates in that population, and the strengths (both absolute and relative) of the association of those covariates with the outcome. That is, the coefficients of a logistic model (including the intercept) determine the prevalence. The same is true regarding the risk ratio and risk difference (if there is one particular exposure or treatment of interest) and the AUC.
Since neither approach will help us out here, I created the function logisticCoefs to fill in the gap. Here we start with the simplest case where we have a target marginal proportion or prevalence, and then illustrate data generation with three other target statistics: risk ratios, risk differences, and AUCs.
Prevalence
In this first example, we start with one set of assumptions for four covariates \(x_1, x2 \sim N(0, 1)\), \(b_1 \sim Bin(0.3)\), and \(b_2 \sim Bin(0.7)\), and generate the outcome y with the following data generating process:
\[ \text{logit}(y) = 0.15x_1 + 0.25x_2 + 0.10b_1 + 0.30b_2\]
library(simstudy)
library(ggplot2)
library(data.table)
coefs1 <- c(0.15, 0.25, 0.10, 0.30)
d1 <- defData(varname = "x1", formula = 0, variance = 1)
d1 <- defData(d1, varname = "x2", formula = 0, variance = 1)
d1 <- defData(d1, varname = "b1", formula = 0.3, dist = "binary")
d1 <- defData(d1, varname = "b2", formula = 0.7, dist = "binary")
d1a <- defData(d1, varname = "y",
formula = "t(..coefs1) %*% c(x1, x2, b1, b2)",
dist = "binary", link = "logit")
set.seed(48392)
dd <- genData(500000, d1a)
dd## Key: <id>
## id x1 x2 b1 b2 y
## <int> <num> <num> <int> <int> <int>
## 1: 1 0.29 0.390 0 1 1
## 2: 2 0.76 -0.925 0 0 0
## 3: 3 -1.47 0.939 0 0 1
## 4: 4 1.92 0.560 0 1 1
## 5: 5 1.40 -0.238 0 1 0
## ---
## 499996: 499996 -0.32 0.367 0 0 0
## 499997: 499997 -1.08 2.152 0 0 0
## 499998: 499998 -1.10 0.380 1 0 0
## 499999: 499999 0.56 -1.042 0 1 0
## 500000: 500000 0.52 0.076 0 1 1The overall proportion of \(y=1\) in this case is
dd[, mean(y)]## [1] 0.56If we have a desired marginal proportion of 0.40, then we can add an intercept of -0.66 to the data generating process:
\[ \text{logit}(y) = -0.66 + 0.15x_1 + 0.25x_2 + 0.10b_1 + 0.30b_2\]
The simulation now gives us the desired target:
d1a <- defData(d1, varname = "y",
formula = "t(c(-0.66, ..coefs1)) %*% c(1, x1, x2, b1, b2)",
dist = "binary", link = "logit")
genData(500000, d1a)[, mean(y)]## [1] 0.4If we change the distribution of the covariates, so that \(x_1 \sim N(1, 1)\), \(x_2 \sim N(2, 1)\), \(b_1 \sim Bin(0.5)\), and \(b_2 \sim Bin(0.8)\), and the strength of the association of these covariates with the outcome so that
\[ \text{logit}(y) = 0.20x_1 + 0.35x_2 + 0.20b_1 + 0.45b_2,\]
the marginal proportion/prevalence (assuming no intercept term) also changes, going from 0.56 to 0.84:
coefs2 <- c(0.20, 0.35, 0.20, 0.45)
d2 <- defData(varname = "x1", formula = 1, variance = 1)
d2 <- defData(d2, varname = "x2", formula = 3, variance = 1)
d2 <- defData(d2, varname = "b1", formula = 0.5, dist = "binary")
d2 <- defData(d2, varname = "b2", formula = 0.8, dist = "binary")
d2a <- defData(d2, varname = "y",
formula = "t(..coefs2) %*% c(x1, x2, b1, b2)",
dist = "binary", link = "logit")
genData(500000, d2a)[, mean(y)]## [1] 0.84But under this new distribution, adding an intercept of -2.13 yields the desired target.
\[ \text{logit}(y) = -2.13 + 0.20x_1 + 0.35x_2 + 0.20b_1 + 0.45b_2 \]
d2a <- defData(d2, varname = "y",
formula = "t(c(-2.13, ..coefs2)) %*% c(1, x1, x2, b1, b2)",
dist = "binary", link = "logit")
genData(500000, d1a)[, mean(y)]## [1] 0.4Finding the intercept
Where did those two intercepts come from? The paper by Peter Austin describes an iterative bisection procedure that takes a distribution of covariates and a set of coefficients to identify the intercept coefficient that yields the target marginal proportion or prevalence.
The general idea of the algorithm is to try out series of different intercepts in an intelligent way that ends up at the right spot. (If you want the details for the algorithm, take a look at the paper.) The starting search range is pre-defined (we’ve used -10 to 10 for the intercept), and we start with an value of 0 for the initial intercept and simulate a large data set (the paper uses 1 million observations, but 100,000 seems to work just fine) and record the population prevalence. If we’ve overshot the target prevalence, we turn our attention to the range between -10 and 0, taking the average, which is -5. Otherwise, we focus on the range between 0 and 10. We iterate this way, choosing the range we need to focus on and setting the intercept at the mid-point (hence the name bisection). The algorithm will converge pretty quickly on the value of the intercept that gives the target population prevalence for the underlying covariate distribution and coefficient assumptions.
In the current implementation in simstudy, the intercept is provided by a simple call to logisticCoefs. Here are the calls for the two sets of definitions in definition tables d1 and d2.
logisticCoefs(defCovar = d1, coefs = coefs1, popPrev = 0.40)## B0 x1 x2 b1 b2
## -0.66 0.15 0.25 0.10 0.30logisticCoefs(defCovar = d2, coefs = coefs2, popPrev = 0.40)## B0 x1 x2 b1 b2
## -2.13 0.20 0.35 0.20 0.45Risk ratios
Just as the prevalence depends on the distribution of covariates and their association with the outcome, risk ratios comparing the outcome probabilities for two groups also depend on the additional covariates. The marginal risk ratio comparing treatment (\(A =1\) to control (\(A=0\)) (given the distribution of covariates) is
\[RR = \frac{P(y=1 | A = 1)}{P(y=1 | A = 0)}\] In the data generation process we use a log-odds ratio of -0.40 (odds ratio of approximately 0.67) in both cases, but we get different risk ratios (0.82 vs. 0.93), depending on the covariates (defined in d1 and d2).
d1a <- defData(d1, varname = "rx", formula = "1;1", dist = "trtAssign")
d1a <- defData(d1a, varname = "y",
formula = "t(c(-0.40, ..coefs1)) %*% c(rx, x1, x2, b1, b2)",
dist = "binary", link = "logit"
)
dd <- genData(500000, d1a)
dd[rx==1, mean(y)]/dd[rx==0, mean(y)]## [1] 0.82d2a <- defData(d2, varname = "rx", formula = "1;1", dist = "trtAssign")
d2a <- defData(d2a, varname = "y",
formula = "t(c(-0.40, ..coefs2)) %*% c(rx, x1, x2, b1, b2)",
dist = "binary", link = "logit"
)
dd <- genData(500000, d2a)
dd[rx==1, mean(y)]/dd[rx==0, mean(y)]## [1] 0.93By specifying both a population prevalence and a target risk ratio in the call to logisticCoefs, we can get the necessary parameters. When specifying the target risk ratio, it is required to be between 0 and 1/popPrev. A risk ratio cannot be negative, and the probability of the outcome under treatment cannot exceed 1 (which will happen if the risk ratio is greater than 1/popPrev).
C1 <- logisticCoefs(d1, coefs1, popPrev = 0.40, rr = 0.85)
C1## B0 A x1 x2 b1 b2
## -0.66 -0.26 0.15 0.25 0.10 0.30If we use \(C_1\) in the data generation process, we will get a data set with the desired target prevalence and risk ratio:
d1a <- defData(d1, varname = "rx", formula = "1;1", dist = "trtAssign")
d1a <- defData(d1a, varname = "y",
formula = "t(..C1) %*% c(1, rx, x1, x2, b1, b2)",
dist = "binary", link = "logit"
)
dd <- genData(500000, d1a)Here are the prevalence and risk ratio:
dd[rx==0, mean(y)]## [1] 0.4dd[rx==1, mean(y)]/dd[rx==0, mean(y)]## [1] 0.86You can do the same for the second set of assumptions.
Risk differences
Risk differences have the same set of issues, and are handled in the same way. The risk difference is defined as
\[ RD = P(y=1 | A = 1) - P(y=1 | A = 0)\]
To get the coefficients related to a population prevalence of 0.40 and risk difference of -0.15 (so that the proportion in the exposure arm is 0.25), we use the rd argument:
C1 <- logisticCoefs(d1, coefs1, popPrev = 0.40, rd = -0.15)
C1## B0 A x1 x2 b1 b2
## -0.66 -0.71 0.15 0.25 0.10 0.30Again, using \(C_1\) in the data generation process, we will get a data set with the desired target prevalence and risk difference:
d1a <- defData(d1, varname = "rx", formula = "1;1", dist = "trtAssign")
d1a <- defData(d1a, varname = "y",
formula = "t(..C1) %*% c(1, rx, x1, x2, b1, b2)",
dist = "binary", link = "logit"
)
dd <- genData(500000, d1a)
dd[rx==0, mean(y)]## [1] 0.4dd[rx==1, mean(y)] - dd[rx==0, mean(y)]## [1] -0.15AUC
The AUC is another commonly used statistic to evaluate a logistic model. (I described the AUC in a post a while back.) We can use logisticCoefs to find the parameters that will allow us to generate data from a model with a specific AUC. To get the coefficients related to a population prevalence of 0.40 and an AUC of 0.85, we use the auc argument (which must be between 0.5 and 1):
C1 <- logisticCoefs(d1, coefs1, popPrev = 0.40, auc = 0.85)
C1## B0 x1 x2 b1 b2
## -1.99 0.85 1.41 0.56 1.69Again, using \(C_1\) in the data generation process, we will get a data set with the desired target prevalence and the AUC (calculated here using the lrm function in the rms package:
d1a <- defData(d1, varname = "y",
formula = "t(..C1) %*% c(1, x1, x2, b1, b2)",
dist = "binary", link = "logit"
)
dd <- genData(500000, d1a)
dd[, mean(y)]## [1] 0.4fit <- rms::lrm(y ~ x1 + x2 + b1 + b2, data = dd)
fit$stats["C"]## C
## 0.85Visualizing the different AUCs
To finish up, here is an application of the logisticCoefs that facilitates visualization of data generated by different prevalence and AUC assumptions. In this case, there are three different scenarios, all based on a single covariate score. The score is used to predict whether an individual is “qualified”. (In the figures, those who are qualified are colored red, those who are not are green.)
In the first scenario, we want to generate data for a sample where 40% are considered “qualified”, though the AUC is only 0.75. In the second scenario, we still assume 40%, but the AUC is 0.95.
d1 <- defData(varname = "score", formula = 0, variance = 1)
C1 <- logisticCoefs(d1, coefs = .3, popPrev = 0.40, auc = .75)
C2 <- logisticCoefs(d1, coefs = .3, popPrev = 0.40, auc = .95)Here are the parameters for each data generating process:
rbind(C1, C2)## B0 score
## C1 -0.49 1.1
## C2 -1.11 3.9Given the higher AUC in the second scenario, we should see more separation between the qualified and non-qualified based on the scores. Indeed, the figure seems to support that:
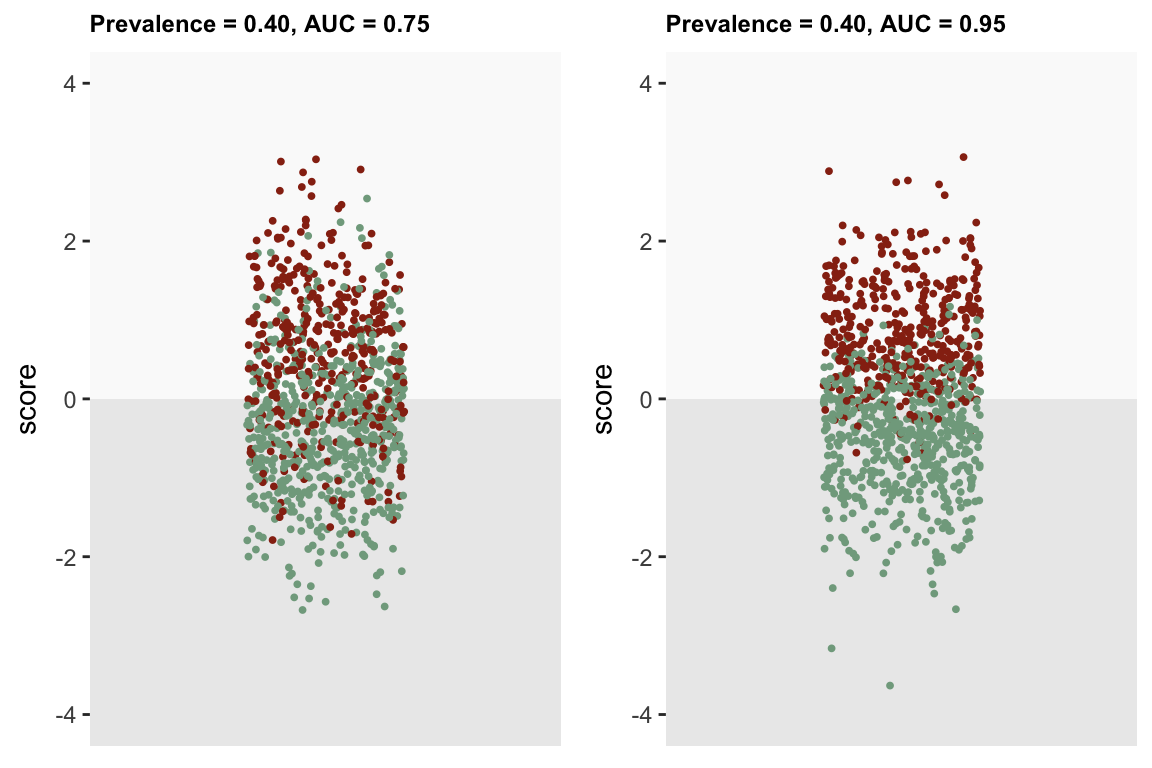
In the third scenario, the proportion of qualified people drops to 20% and the AUC based on the model with the score is 0.75:
C3 <- logisticCoefs(d1, coefs = .3, popPrev = 0.20, auc = .75)
rbind(C1, C3)## B0 score
## C1 -0.49 1.1
## C3 -1.69 1.1We see fewer red dots overall in the right hand plot, but the separation between qualified and unqualified is not noticeably different:
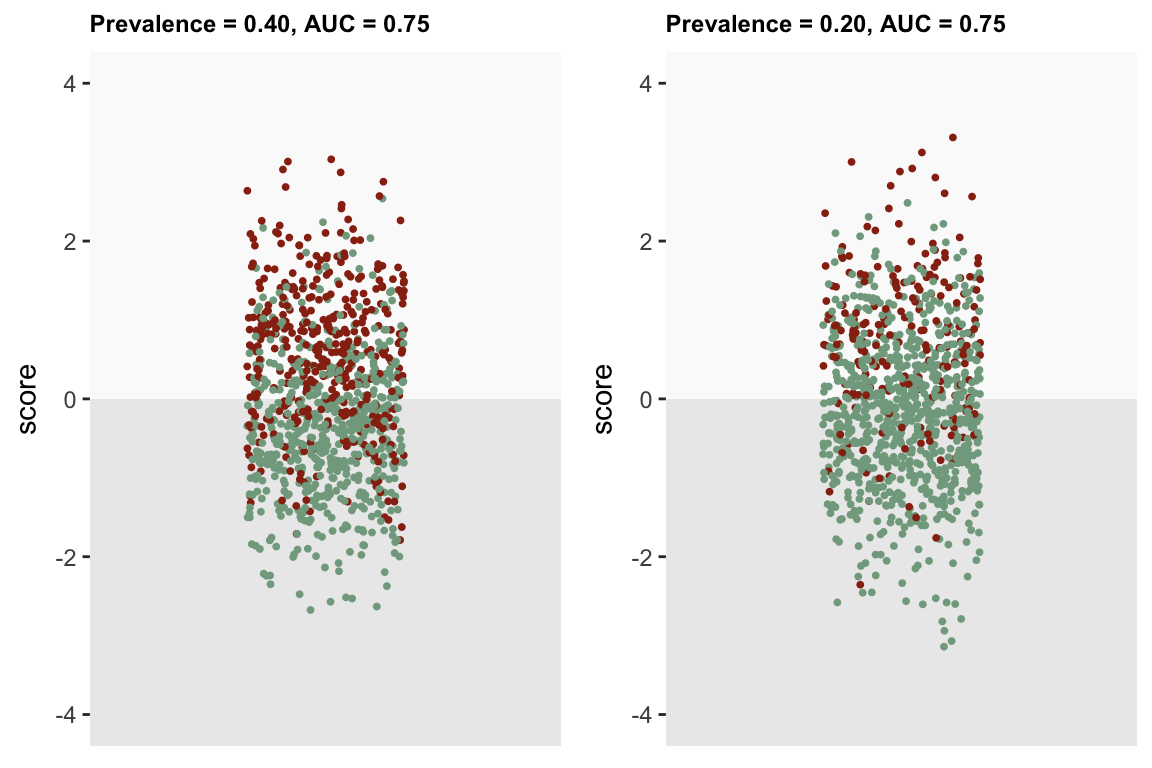
References:
Austin, Peter C. “The iterative bisection procedure: a useful tool for determining parameter values in data-generating processes in Monte Carlo simulations.” BMC Medical Research Methodology 23, no. 1 (2023): 1-10.